以技术之名周报02#X86-汇编| 2020-04-05
Part01 - 知识准备
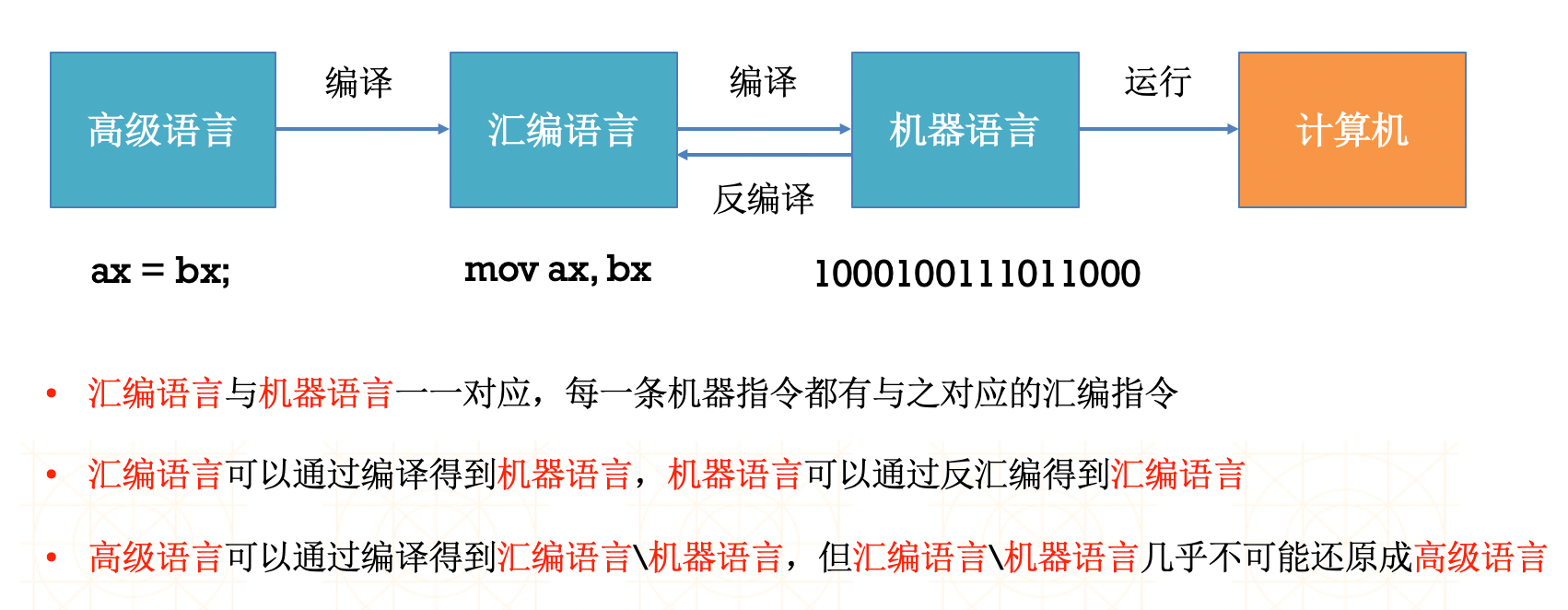
在介绍汇编之前,我们首先应该搞清楚什么是机器语言?什么是汇编语言?什么是高级语言?
机器语言:
机器语言是用二进制代码表示的计算机能直接识别和执行的一种机器指指令系统令的集合。
汇编语言:
汇编语言是任何一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。在不同的设备中,汇编语言对应着不同的机器语言指令集。一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。汇编语言使用助记符(Mnemonics)来代替和表示特定低级机器语言的操作。
高级语言:
高级编程语言是高度封装了的编程语言,与低级语言相对。它是以人类的日常语言为基础的一种编程语言,使用一般人易于接受的文字来表示,有较高的可读性,以方便对电脑认知较浅的人亦可以大概明白其内容。比如:C、C++、Swift、Java…
用一张图来解释这三种语言之间的关系:
Part02 - 编译器:LLVM
汇编严重依赖硬件设备, iOS模拟器使用AT&T格式汇编(因为 Mac 是基于 Unix 开发的), iOS 真机使用ARM汇编
。
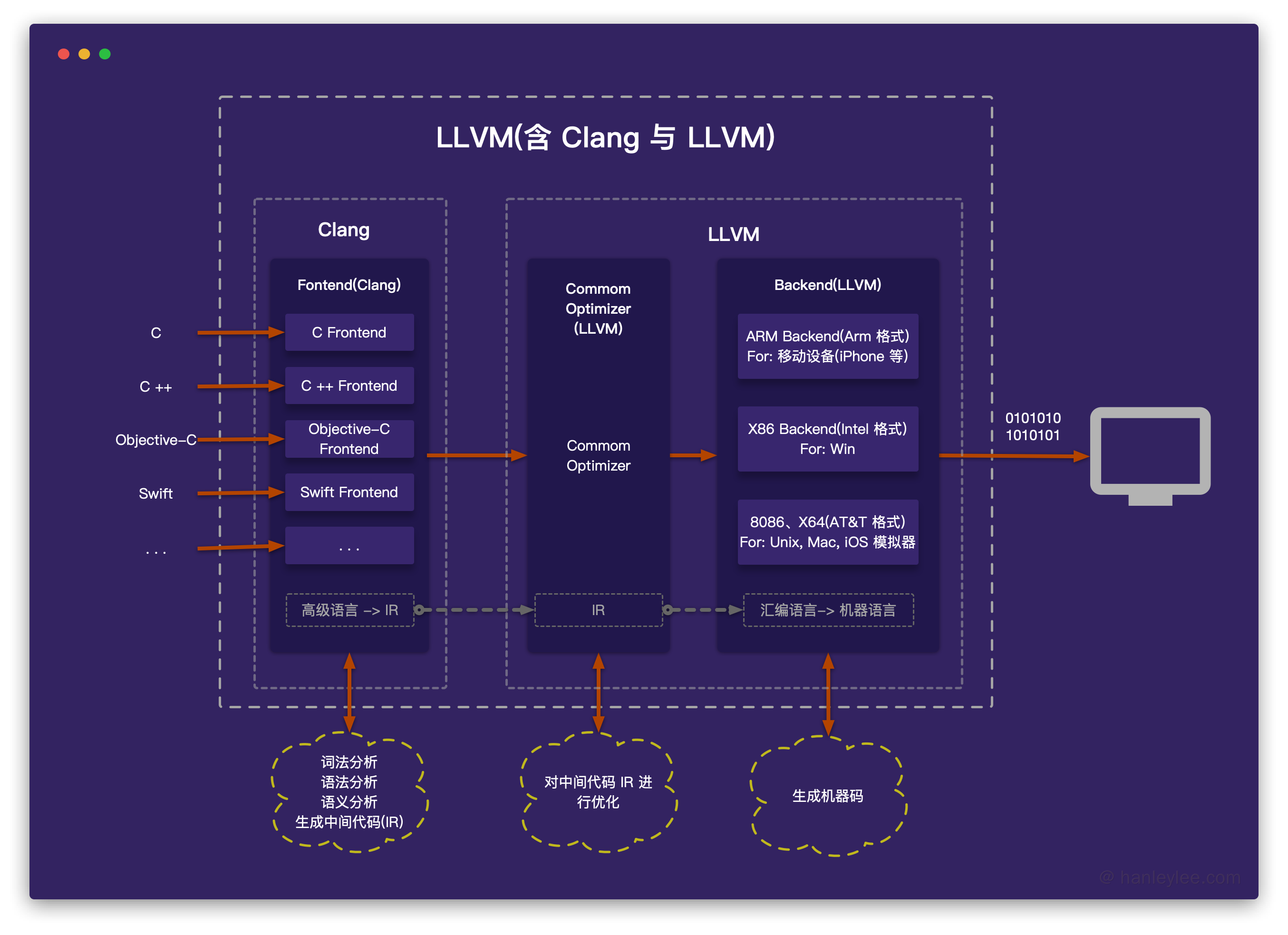
Xcode内置的编译器是LLVM,LLVM 是一个著名的编译器, 由大神 Chris Lattner 开发, 可用于常规编译器, JIT编译器, 汇编器, 调试器, 静态分析工具等一系列跟编程语言相关的工作。
LLVM 的编译架构分为三个阶段
- 前端:进行语法分析, 语义分析, 生成中间代码。实际上在 Xcode 中写代码的时候会实时提示错误就是因为持续在调用 LLVM 的前端部分
- 公用优化器:将生成的中间文件进行优化, 去除冗余代码, 进行结构优化。
- 后端:将优化后的中间代码再次转换, 变为汇编语言, 再次进行优化. 最后将各个文件代码转换为二进制代码(机器语言)并链接以生成一个可执行文件。
LLVM 架构的优点
- 不同的前端后端使用统一的中间代码LLVM Intermediate Representation (LLVM IR)
- 如果需要支持一种新的编程语言, 那么只需要实现一个新的前端(Swift 就是新增了一个针对于 Swift 的前端)
- 如果需要支持一种新的硬件设备, 那么只需要实现一个新的后端
- 优化阶段是一个通用的阶段, 它针对的是统一的LLVM IR, 不论是支持新的编程语言, 还是支持新的硬件设备, 都不需要对优化阶段做修改
- LLVM现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC家族, Java, .NET, Python, Ruby, Scheme, Haskell, D等)
Part03 - 汇编语言种类及选择:
汇编语言种类
AT&T格式(UNIX,MAC阵营):8086汇编(16bit 架构)x64汇编(64bit 架构)Intel格式(WIN阵营):x86汇编(32bit 架构)ARM格式 (移动设备阵营): 只用在arm处理器上
汇编语言选择
虽然不同的架构对应着不同的汇编语言,但是原理基本上是一样的,为了调试方便,我们将以X86-64架构来探究Swift中函数调用的本质。
Part04 - AT&T汇编
寄存器和数据类型
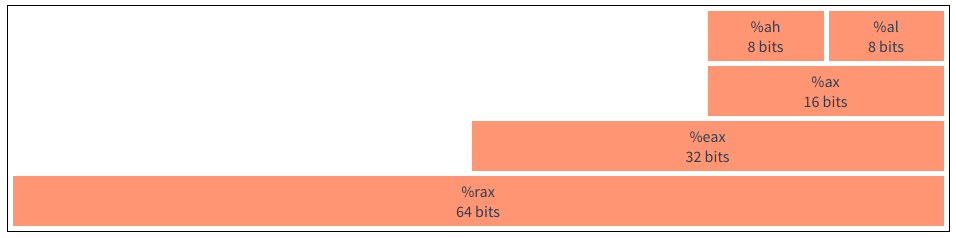
X86-64有16个通用(几乎都是通用的)64位整数寄存器:
| %rax | %rbx | %rcx | %rdx | %rsi | %rdi | %rbp | %rsp | %r8 | %r9 | %r10 | %r11 | %r12 | %r13 | %r14 | %r15 |
|---|
因为早期处理器的不同寄存器的用途不同,并不是所有的指令都可以应用于每个寄存器。(现在基本上都是通用寄存器了)随着设计的发展,增加了新的指令和寻址模式,使各种寄存器几乎相等。除了几条特殊的指令,比如与字符串处理有关的指令,需要使用%rsi和%rdi,另外,还有两个寄存器保留用作堆栈指针(%rsp)和基址指针(%rbp)。最后的八个被编号的寄存器没有特别的限制。除此之外还有一个特殊的寄存器%rip(instruction pointer),一般情况下你不需要关注这个寄存器,但是这个寄存器很重要,你需要知道他的功能,后面在说函数调用时会提及。
多年来X86架构已经从8位扩展到了32位,因此每个寄存器都有一些内部结构如下图:
寻址模式
什么是寻址模式?就是数据在内存寄和寄存器之间进行移动时,取得数据地址的不同表达方式。最常用的寻址的汇编指令是mov。x86-64使用的是复杂指令集(cisc),因此mov有许多不同的变体,可以在不同单元之间移动不同类型的据。mov与大多数指令一样,具有单字母后缀,用于确定要移动的数据量。下表用于描述各种大小的数据值:
| 前缀 | 全称 | Size |
|---|---|---|
| B | byte | 1byte(8 bits) |
| W | word | 2byte(16 bits) |
| L | long | 4byte(32 bits) |
| Q | quadword | 8byte(64 bits) |
MOVB移动一个字节,MOVW移动一个字,MOVL移动一个长整形,MOVQ移动一个四字。一般来说,MOV指令移动数据的大小必须与后缀匹配。虽然可以忽略后缀,汇编器将尝试根据参数选择合适的MOV指令。但是,不推荐这样做,因为它可能会造成预料之外的结果。
对于AT&T语法使用MOV寻址时需要两个参数,第一个参数是源地址,第二个参数是目标地址。原地址的表达方式不一样那么寻址的方式也就不一样。比如,访问全局变量使用一个简单变量的名称比如x,我们称之为全局符号寻址。printf一个整数常量,由美元符号+数值表示(例如$ 56),我们称之为直接寻址。访问寄存器的值直接使用寄存器的名字如 %rbx,我们称之为寄存器寻址。如果寄存器中存放的是一个地址,访问这个地址中的数据时需要在寄存器外面加上括号如(%rbx),我们称之为间接寻址。如果寄存器中存放的是一个数组的地址,我们需要访问数组中的元素时可能需要操作这个地址进行偏移,如8(%rcx)是指%rcx中存放的的地址加8字节存储单元的值,我们称之为相对基址寻址(此模式对于操作堆栈,局部变量和函数参数非常重要)。在相对基址寻址上有各种复杂的变化,例如-16(%rbx,%rcx,8)是指地址-16 +%rbx +%rcx * 8处的值。此模式对于访问排列在数组中的特殊大小的元素非常有用。
以下是使用各种寻址模式将64位值加载到%rax的示例:
| 寻址模式 | 示例 |
|---|---|
| 全局符号寻址(Global Symbol) | MOVQ x, %rax |
| 直接寻址(Immediate) | MOVQ $56, %rax |
| 寄存器寻址(Register) | MOVQ %rbx, %rax |
| 间接寻址(Indirect) | MOVQ (%rsp), %rax |
| 相对基址寻址(Base-Relative) | MOVQ -8(%rbp), %rax |
| 相对基址偏移缩放寻址(Offset-Scaled-Base-Relative) | MOVQ -16(%rbx,%rcx,8), %rax |
通常,可以使用相同的寻址模式将数据存储到寄存器和内存。但是,并不是所有模式都支持。比如不能对MOV的两个参数都使用base-relative mode。像MOVQ -8(%rbx),-8(%rbx)这样是不行的。要准确查看支持哪些寻址模式组合,您必须阅读相关指令的手册。
基础运算指令
编译器需要四个基本的算术指令: ADD, SUB, IMUL, 和IDIV(加减乘除)。add和sub有两个操作数:一个来源值和一个被操作数。例如,这条指令:
1 | addq %rbx, %rax |
将%rbx添加到%rax,并将结果放在%rax中,覆盖之前可能存在的内容。这就要求你在使用寄存器时要小心。 例如,假设你想计算 c = b *(b + a),其中a和b是全局整数。要做到这一点,你必须小心,在执行加法时不要覆盖b的值。这里有一个实现:
1 | movq a, %rax |
imul指令有点不太一样:它将其参数乘以%rax的内容,然后将结果的低64位放入%rax,将高64位放入%rdx。(将两个64位数字相乘会产生一个128位数字。)
idiv指令和乘法指令差不多:它以一个128位整数值开始,其低64位位于%rax,高位64位位于%rdx中,并将其除以参数。(CDQO指令用于将%rax符号扩展为%rdx,以便正确处理负值。)商被放在%rax中,余数放在%rdx中。例如,除以5:
1 | movq a, %rax # set the low 64 bits of the dividend |
大多数语言中的求模指令只是利用%rdx中剩余的余数,指令INC和DEC分别递增和递减寄存器。例如,语句a = ++ b可以翻译为:
1 | movq b, %rax |
布尔操作的工作方式非常类似:AND,OR,和XOR指令需要两个参数,而NOT指令只需要一个参数。像MOV指令一样,各种算术指令可以在各种寻址模式下工作。但是,您可能会发现使用MOV将值载入和载出寄存器是最方便的,然后仅使用寄存器来执行算术运算。
比较和跳转指令
使用JMP指令,我们可以创建一个简单的无限循环,使用%eax寄存器从零开始计数:
1 | movq $0, %rax |
为了定义更有用的程序结构,如终止循环和if-then等语句,我们必须有一个可以改变程序流程的机制。在大多数汇编语言中,这些处理由两种不同的指令处理:比较和跳转。
所有的比较都是通过CMP指令完成的。CMP比较两个不同的寄存器,然后在内部EFLAGS寄存器中设置几个位,记录这些值是相同,更大还是更小。你不需要直接看EFLAGS寄存器的值。而是根据结果的不同来做适当的跳转:
| 指令 | 意义 |
|---|---|
| je | 如果大于则跳转 |
| jne | 如果不等于则跳转 |
| jl | 如果小于则跳转 |
| jle | 如果小于等于则跳转 |
| jg | 如果大于则跳转 |
| jge | 如果大于等于则跳转 |
举个例子,这里是一个循环来使%rax从0到5:
1 | movq $0, %rax |
再举个例子,一个条件赋值:如果全局变量x>=0,那么全局变量y=10,否则 y=20:
1 | movq x, %rax |
跳转的参数是目标标签。这些标签在一个汇编文件中必须是唯一且私密的,除了包含在.globl内的标签 ,其他标签不能在文件外部看到,也就是不能在文件外调用。用c语言来说,一个普通的汇编标签是static的,而.globl标签是extern
其他常用寄存器指令
leaq %rbp,%rax: 内存赋值lea, 将rbq的内存地址值赋给raxxorl %eax, %eax: 异或xor, 将eax清0, 自己异或自己jmp 0x80001: 跳转jmp, 跳转到函数地址为0x80001的地址jmp *(%rax): 间接跳转*(),rax是个内存地址,*(rax)是拿到rax地址里的值callq 0x80001: 函数调用call, 调用地址为0x80001的函数, 一般配合retq
栈
栈是一种辅助数据结构,主要用于记录程序的函数调用历史记录以及不适合寄存器的局部变量。栈从高地址向低地址增长。%rsp寄存器被称为“栈指针”并跟踪堆栈中最底层(也就是最新的)的数据。因此,要将%rax压入堆栈,我们必须从%rsp中减去8(%rax的大小,以字节为单位),然后写入%rsp指向的位置:
1 | subq $8, %rsp |
从栈中弹出一个值与上面的操作相反:
1 | movq (%rsp), %rax |
从栈中丢弃最新的值,只需移动堆栈指针即可:
1 | addq $8, %rsp |
当然,压栈(入栈)或出栈是经常使用到的操作,所以都有简化的单条指令,其行为与上面的完全一样:
1 | pushq %rax |
函数调用
所有c标准库中可用的函数也可以在汇编语言程序中使用。以一种称为“调用约定”的标准方式调用,以便用多种语言编写的代码都可以链接在一起。
在x86 32位机器中。调用约定只是将每个参数入栈,然后调用该函数。被调用函数在栈中查找参数,完成它的工作之后,将结果存储到单个寄存器中。然后调用者弹出栈中的参数。
Linux上x86-64使用的调用约定有所不同,称之为System V ABI。完整的约定相当复杂,但以下是对我们来说足够简单的解释:
- 整数参数(包括指针)按顺序放在寄存器%rdi,%rsi,%rdx,%rcx,%r8和%r9中。
- 浮点参数按顺序放置在寄存器%xmm0-%xmm7中。
- 超过可用寄存器的参数被压入栈。
- 如果函数使用可变数量的参数(如printf),那么必须将%eax寄存器设置为浮点参数的数量。
- 被调用的函数可以使用任何寄存器,但如果它们发生了变化,则必须恢复寄存器%rbx,%rbp,%rsp和%r12-%r15的值。
- 函数的返回值存储在%eax中。
| 寄存器 | 用途 | 是否需要保存 |
|---|---|---|
| %rax | 保存返回结果 | 无需保存 |
| %rbx | - | 被调用者保存 |
| %rcx | 参数4 | 无需保存 |
| %rdx | 参数3 | 无需保存 |
| %rsi | 参数2 | 无需保存 |
| %rdi | 参数1 | 无需保存 |
| %rbp | 栈基址指针 | 被调用者保存 |
| %rsp | 栈指针 | 被调用者保存 |
| %r8 | 参数5 | 无需保存 |
| %r9 | 参数6 | 无需保存 |
| %r10 | - | 调用者保存 |
| %r11 | - | 调用者保存 |
| %r12 | - | 被调用者保存 |
| %r13 | - | 被调用者保存 |
| %r14 | - | 被调用者保存 |
| %r15 | - | 被调用者保存 |
每个函数都需要使用一系列寄存器来执行计算。然而,当一个函数被另一个函数调用时会发生什么?我们不希望调用者当前使用的任何寄存器被调用的函数破坏。为了防止这种情况发生,每个函数必须保存并恢复它使用的所有寄存器,方法是先将它们入栈,然后在返回之前将它们从堆栈弹出。在函数调用的过程中,栈基址指针%rbp始终指向当前函数调用开始时栈的位置,栈指针%rsp始终指向栈中最新的元素对应的位置。%rbp和%rsp之间的元素被我们成为"栈帧",也叫"活动记录"。函数的调用过程其实就是栈帧被创建,扩张然后被销毁的过程。在说明函数调用流程前,我们不得不提到 %rip(instruction pointer) 指令指针寄存器。%rip中存放的是CPU需要执行的下一条指令的地址。每当执行完一条指令之后,这个寄存器会自动增加(可以这样理解)以便指向新的指令的地址。有了这些基础,接下来我们以一段完整的程序代码来解释函数的调用流程,有下面一段c代码:
1 | #include <stdio.h> |
编译为汇编代码之后,为了方便读代码,我们去除一些不需要的指示段之后得到如下代码:
1 | .file "main.c" |
我们知道linux系统中main函数是由glibc中的 exec()簇 函数调用的,比如我们从shell环境中启动程序最终就是由 execvp()调用而来。我们这里不展开说明,你只需要知道main函数其实也是被调用的函数。我们从main函数的第一条指令开始:
1 | main: |
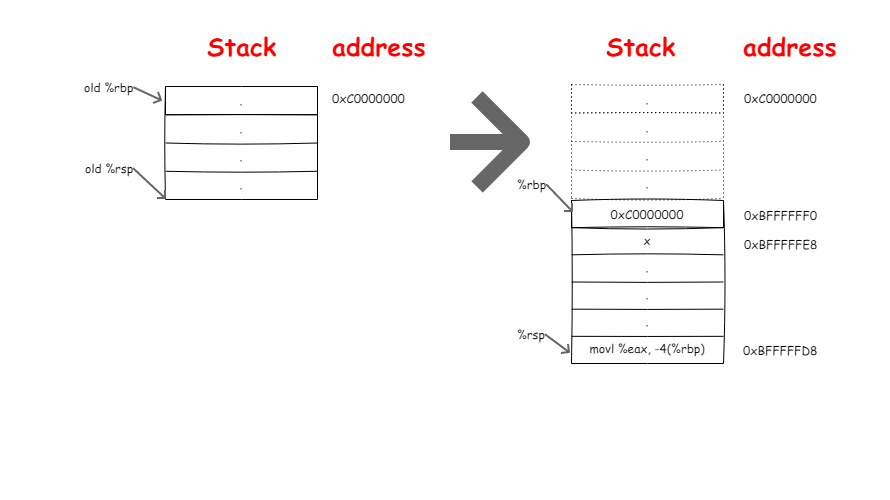
首先,将当前的栈基址指针%rbp入栈,函数调用结束后我们就可以从栈中取得函数调用前%rbp指向的位置,进而恢复栈到之前的样子。然后使当前栈指针指向新的位置。然后
1 | subq $16, %rsp |
在栈上申请16字节的空间以便存放后面的临时变量x,然后根据System V ABI的调用约定将传递给sum函数的参数放入%esi和%edi中(因为是int类型占用4个字节,所以只需要用寄存器的低4字节即可)。这里你可能会发现编译器没有将需要调用者保存的%r10和%r11入栈,因为编译器知道在main函数中不会使用到%r10和%r11寄存器所以无需保存。然后发出调用指令:
1 | call sum |
需要注意以上的CALL指令等同于:
1 | pushq %rip |
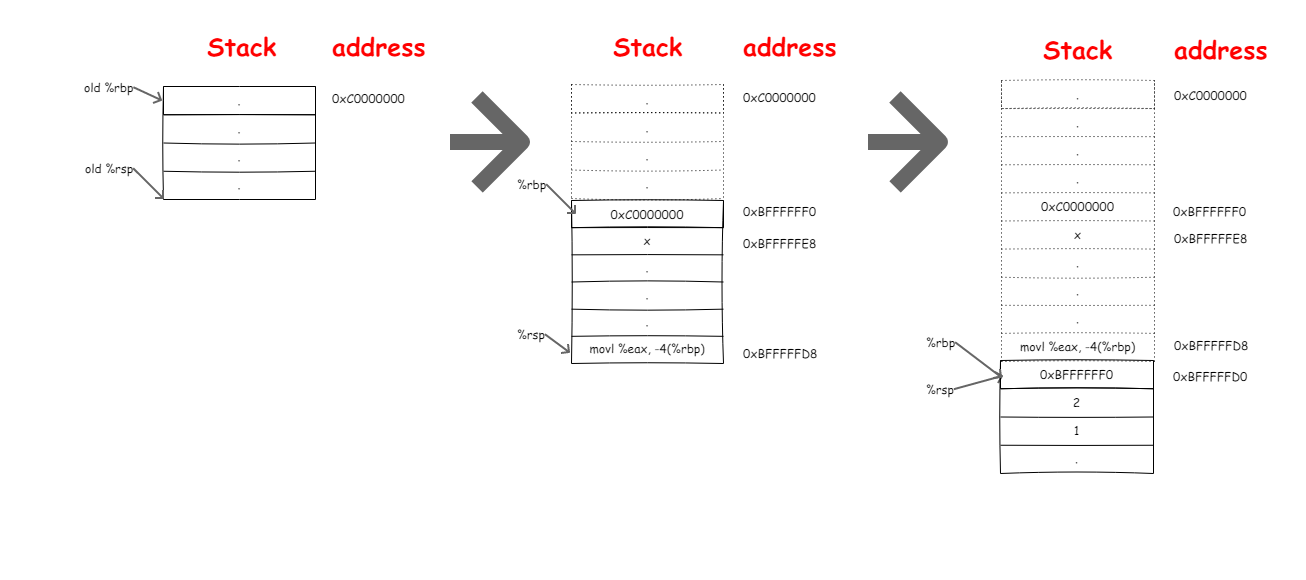
我们把%rip当前的内容放入栈中,以便函数sum调用结束我们可以知道接下来该执行哪条指令,我们假设栈从0xC0000000处开始向低处延伸。到这个阶段栈的变化过程如下所示:
现在程序跳转到sum处执行计算:
1 | pushq %rbp |
和main函数被调用一样,sum函数被调用时,首先也是保存%rbp,然后更新栈指针%rsp,将两个参数拷贝到栈中进行使用。在这里你可能看到了和main 函数不一样的地方,局部变量保存在栈中并没有像main函数中那样引起%rsp的移动(对比main函数中的SUBQ 16)。是因为编译器知道sum中不会再调用其它函数,也就不用保存数据到栈中了,直接使用栈空间即可。所以就无需位移%rsp。计算完成后结果保存在%eax中,现在我们更新一下栈的变化:
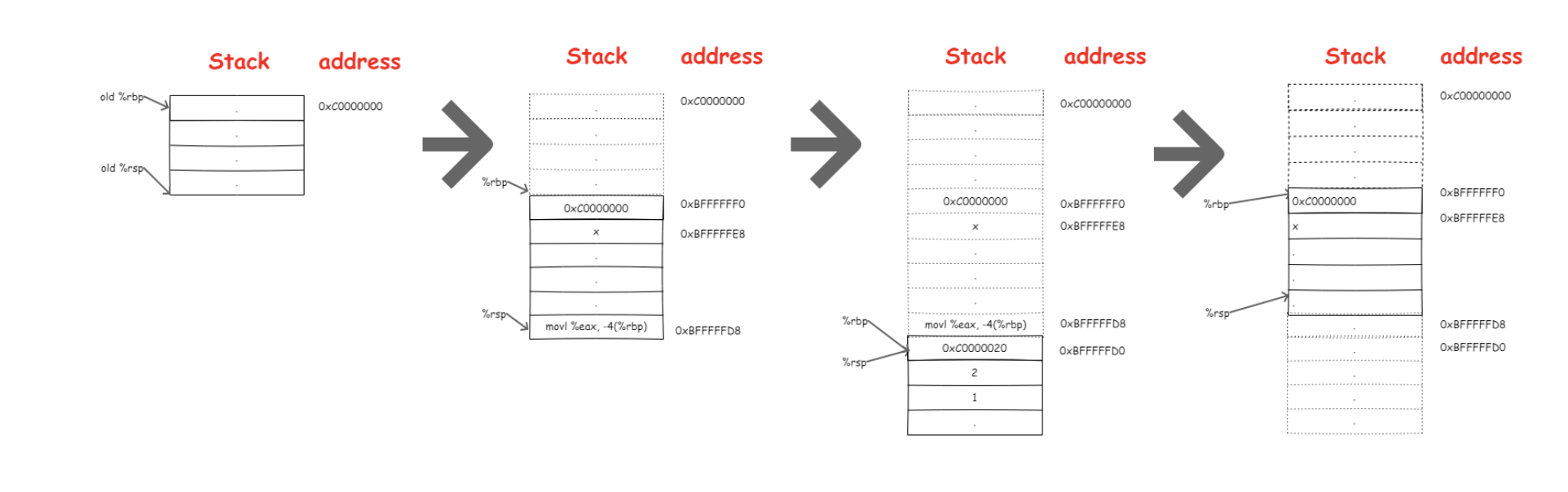
然后返回到main函数时执行了如下操作:
1 | popq %rbp |
先恢复调用前的栈基址指针%rbp,然后此时栈顶的元素就是函数调用之后需要执行的下一条指令的地址,RET指令等价于:
1 | popq %rip |
这样就可以跳转到函数结束后的下一条指令 “movl %eax, -4(%rbp)”处继续执行,至此我们看一下完整调用过程中栈的变化:
更多关于寄存器的知识可以看这篇博客,讲的更加详细
Part05 - LLDB常用指令
了解了汇编的基本指令时候,我们需要再了解在Xcode中如何使用LLDB指令来调试汇编代码
- 读取寄存器的值
1 | register read/ |
- 修改寄存器的值
1 | register write |
- 读取内存中的值
1 | x/数量-格式-字节大小 |
- 修改内存中的值
1 | memory write 内存地址 数值 |
- 格式
1 | x 是十六进制,f是浮点,d是十进制, |
- 字节大小
1 | b - byte 1 字节 |
- 单步运行,把子函数当作一个整体,一步执行(源码级别)
1 | thread step-over、next、n |
- 单步运行,遇到子函数会进入子函数(源码级别)
1 | thread step-in 、 step、s |
- 单步运行,把子函数当作一个整体一步执行(汇编级别)
1 | thread step-inst-over 、 nexti、ni |
- 单步运行,遇到子函数会进入子函数(汇编级别)
1 | thread step-inst 、 stepi、si |
- 直接执行完当前函数的所有代码,返回上一个函数(遇到断点会卡住)
1 | thread step-out 、finish |
Part06 - Swift汇编例子
- 新建一个
Command Line Tool工程,并在main.swift文件中新建一个sum函数
1 | func sum( a: Int, b: Int) -> Int{ |
Xcode进入汇编调试模式,并在main函数中调用sum函数
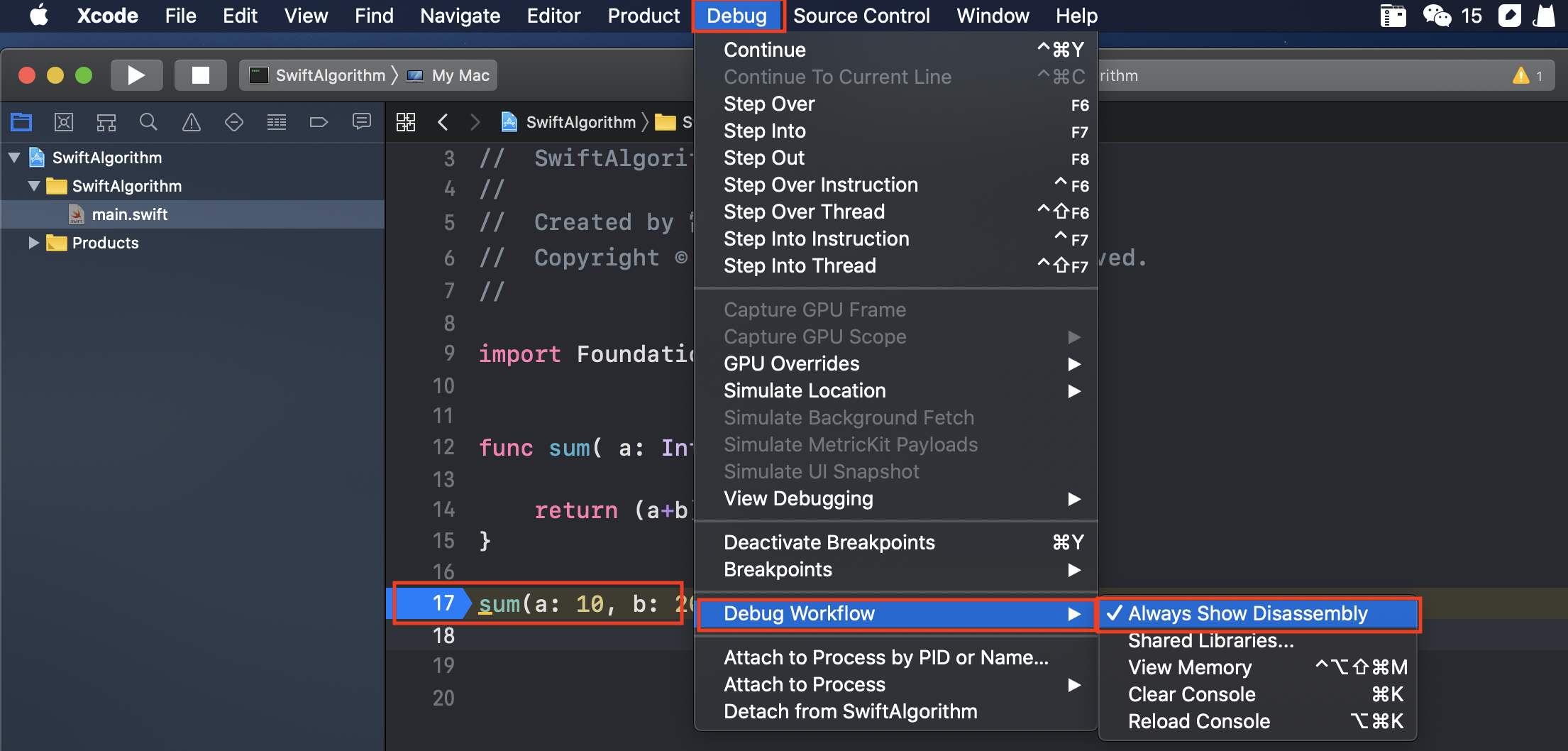
3.在main函数中,调用sum函数,在调用sum函数地方打断点
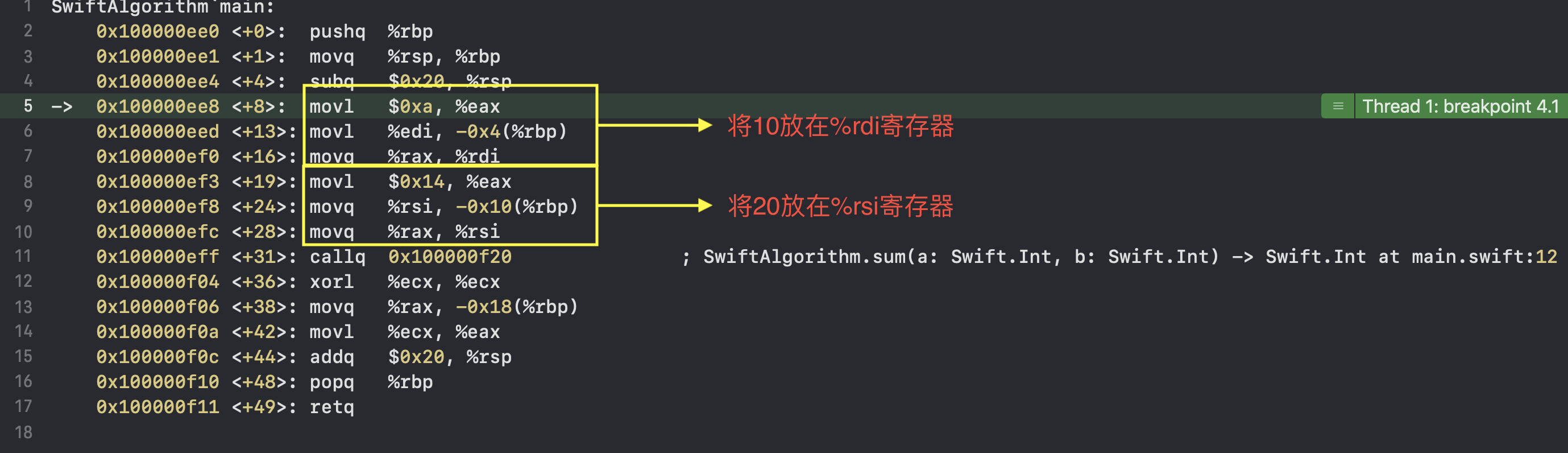
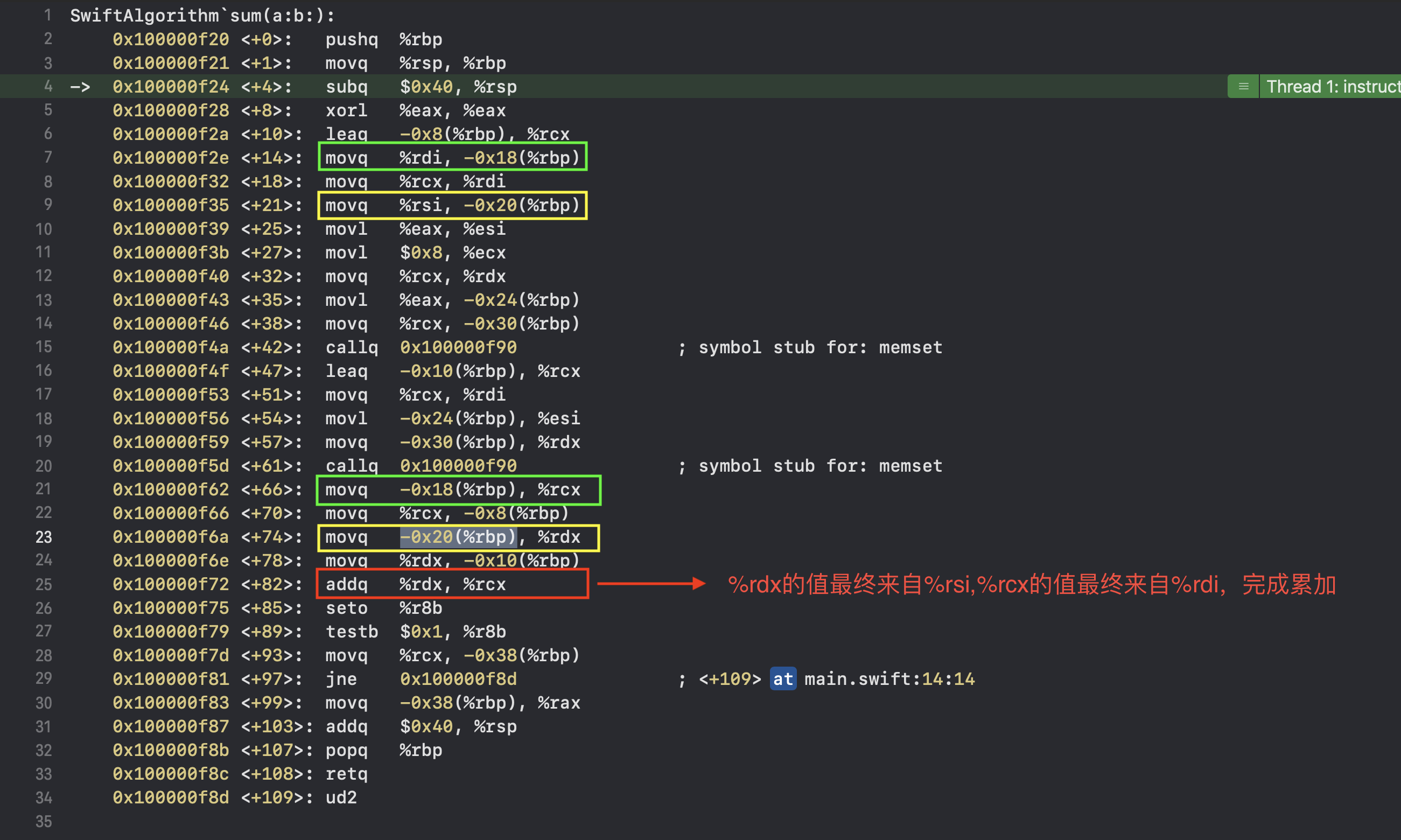
4.通过在控制台执行 n指令,可以定位到第11行,执行si指令可以进入sum函数,在sum函数中,我们可以看到最终通过%rdx和%rcx完成累加,并最终将值放如%rax寄存器,作为函数返回值
Part07 - 参考
x86-64汇编入门
iOS 之编译
x86-64 下函数调用及栈帧原理
从 简单汇编基础 到 Swift 不简单的 a + 1